
How to Show Up in ChatGPT Results: A Strategic Guide to Answer Engine Optimization and AI Visibility in 2025 and Beyond
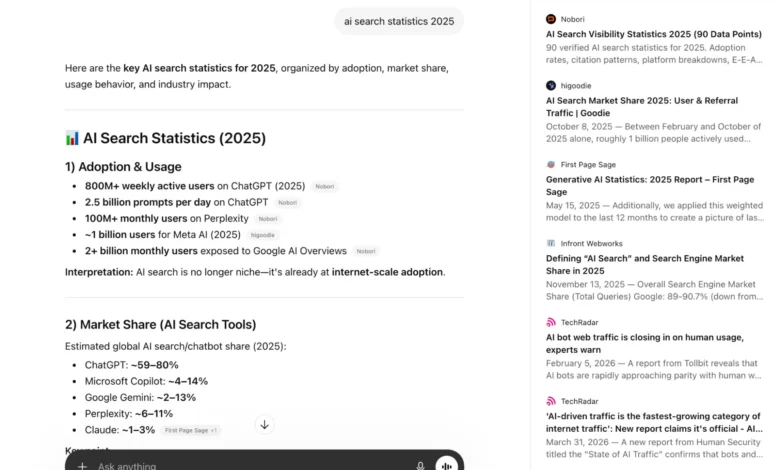
The landscape of digital marketing has undergone a seismic shift as traditional search engine optimization (SEO) is increasingly supplemented, and in some cases supplanted, by Answer Engine Optimization (AEO). As generative AI platforms like ChatGPT become the primary interface for information retrieval, businesses are pivoting their strategies to ensure their content is not just indexed by Google, but cited by Large Language Models (LLMs). Recent industry data underscores the urgency of this transition; for instance, HubSpot reported a 1,850% increase in qualified leads in 2025 directly attributed to a specialized AEO strategy. This evolution marks a departure from the "ten blue links" era of search, moving toward a conversational paradigm where visibility is defined by being the authoritative source for an AI’s synthesized response.
The Dual Architecture of ChatGPT Information Sourcing
To understand how to achieve visibility within ChatGPT, one must first distinguish between the two primary methods the platform uses to generate answers: internal training data and live web search. These two channels require different optimization approaches, as they represent different "memories" within the AI model.
Training Data and the Knowledge Cut-off
OpenAI trains its GPT models on astronomical volumes of data harvested from the public internet, third-party partnerships, and user-provided information. This training allows the model to learn linguistic patterns, conceptual relationships, and factual data. However, this information is static. Every model has a "knowledge cut-off date," which represents the point at which its training data was last finalized. For the GPT-5.4 model, this cut-off is cited as August 2025. Information appearing after this date cannot be "known" by the model’s internal weights unless it utilizes its secondary retrieval mechanism.

Live Web Search and Retrieval Augmented Generation (RAG)
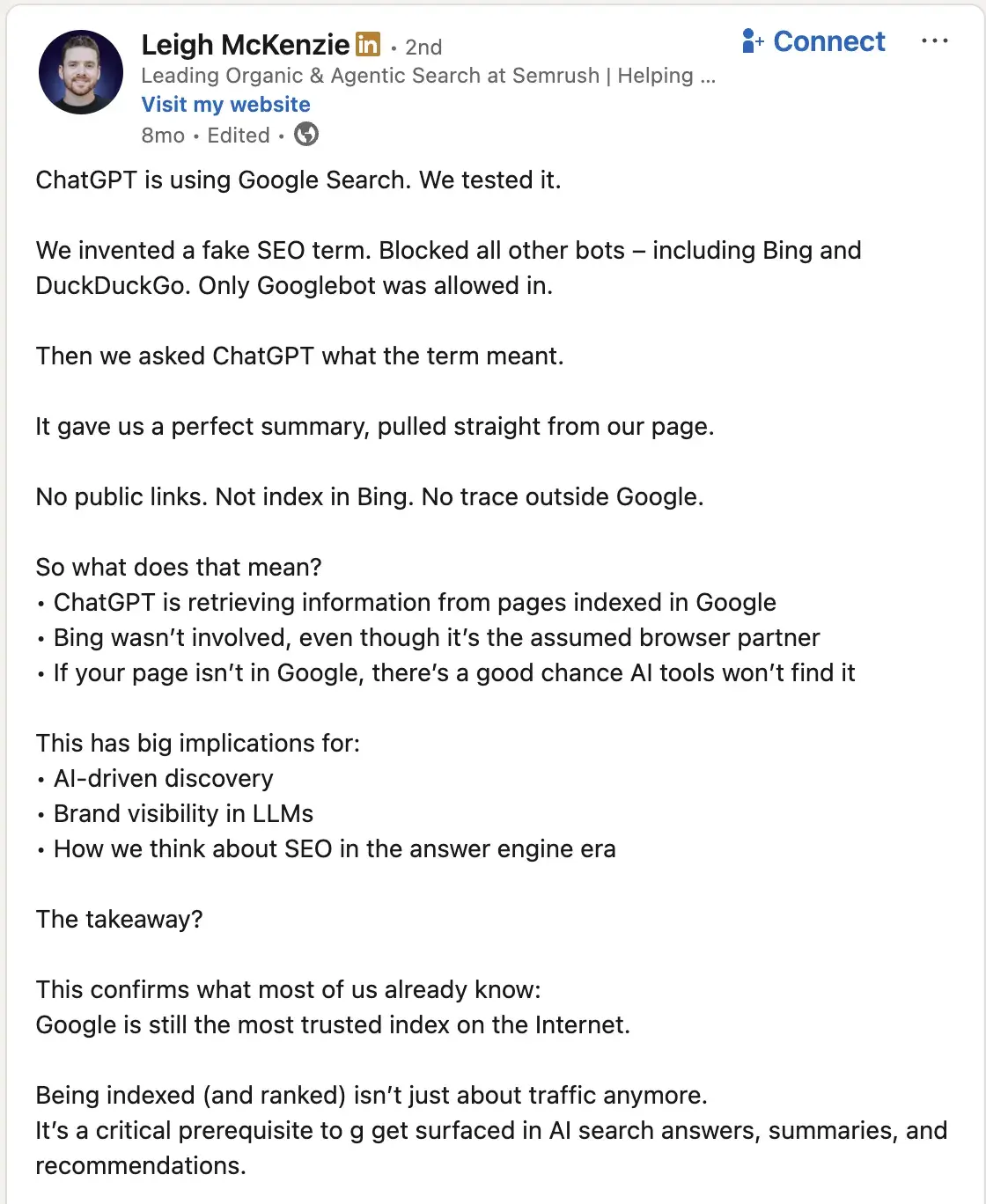
When a user query involves current events, time-sensitive pricing, or information post-dating the knowledge cut-off, ChatGPT initiates a live web search. While OpenAI primarily utilizes Bing as its search provider—particularly for Enterprise and Education tiers—empirical evidence and independent experiments suggest that the platform also leverages Google Search to verify and cite sources.
The distinction between a Google search result and a ChatGPT search result is often stark. In many instances, there is zero overlap between the top five organic results on a Google Search Engine Results Page (SERP) and the sources cited by ChatGPT for the same query. This discrepancy indicates that ChatGPT weighs authority, directness, and technical crawlability differently than traditional search algorithms, offering a "second chance" for brands that may struggle to rank on the first page of Google but possess highly relevant, structured content.
Technical Foundations: Crawling and Indexing for AI
Before a brand can influence an AI’s response, it must ensure that the AI’s "scouts"—its web crawlers—can access and interpret the site’s data. This requires a nuanced management of the robots.txt file and a move away from client-side rendering.
Managing OpenAI Crawlers
OpenAI employs two distinct crawlers: GPTBot and OAI-SearchBot. GPTBot is used to harvest data for future model training, whereas OAI-SearchBot is specifically designed to find content for the live search feature. Marketers must ensure their robots.txt file is configured to allow these bots. A common strategy for privacy-conscious firms is to allow OAI-SearchBot to ensure search visibility while potentially blocking GPTBot to prevent their intellectual property from being used to train future iterations of the model.
The JavaScript Barrier
One of the most frequent technical failures in AI visibility is an over-reliance on JavaScript. While modern browsers can easily render JavaScript-heavy sites, AI crawlers like OAI-SearchBot often struggle with client-side rendering. If the primary content of a page is not present in the initial HTML response, the AI may perceive the page as empty. Experts recommend implementing server-side rendering (SSR) or pre-rendering to ensure that the AI sees the full text of an article immediately upon crawling.
Content Engineering: The "Answer-First" Paradigm
The editorial structure of content must change to accommodate the way LLMs parse information. Unlike human readers who may enjoy a narrative build-up, AI models prioritize "entity-rich" statements and direct definitions located at the beginning of a document.
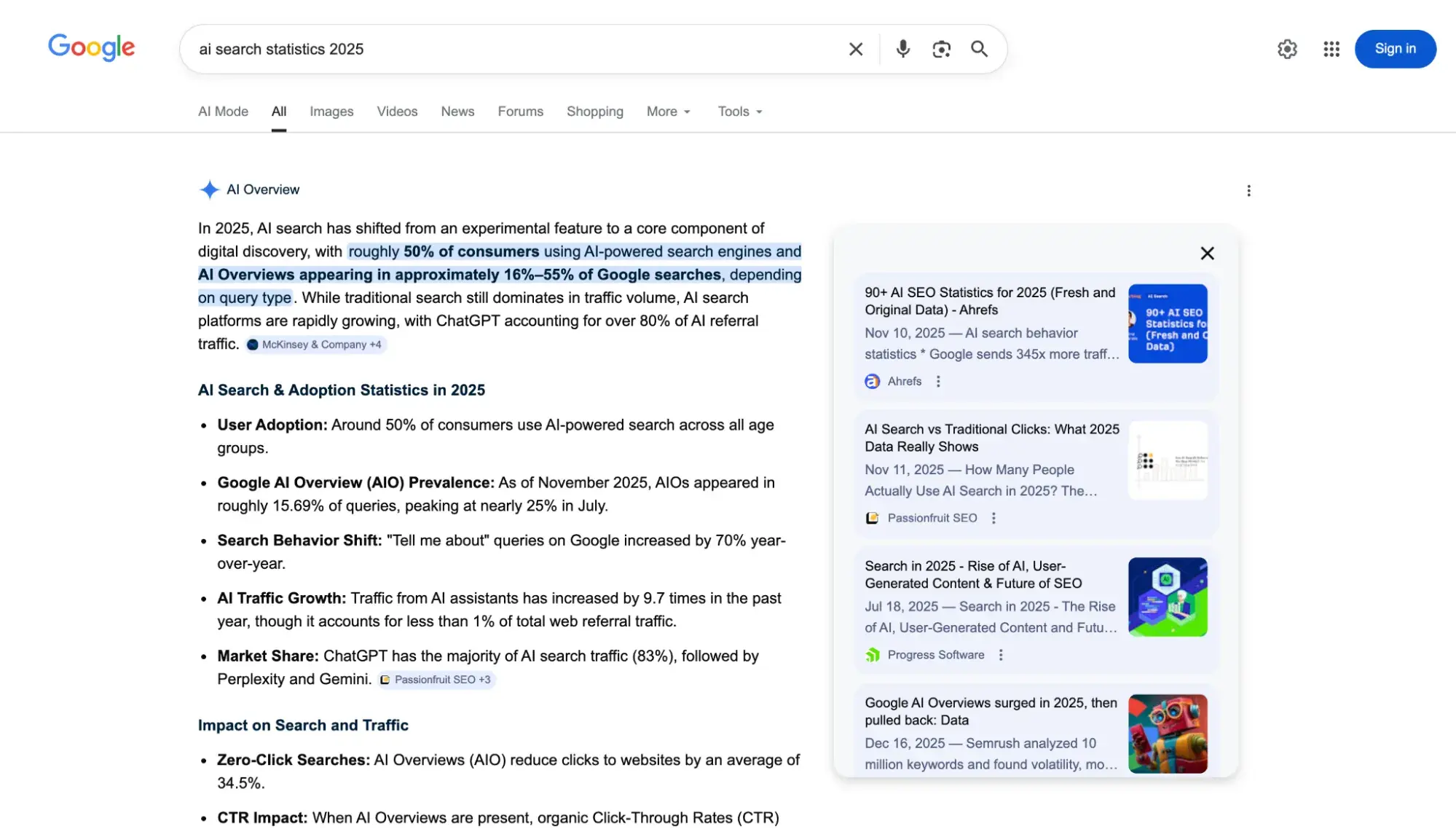
The 30% Rule
Research into AI citations has revealed a significant correlation between information placement and citation likelihood. An analysis of over 18,000 ChatGPT citations conducted in early 2026 found that approximately 44.2% of citations were drawn from the top 30% of a page’s content. A similar study of Google’s AI Overviews found that 55% of cited sources came from the same upper-third of the page. This suggests that the "inverted pyramid" style of journalism—leading with the most critical facts—is the optimal structure for AEO.
Query Fan-Out and Prompt Research
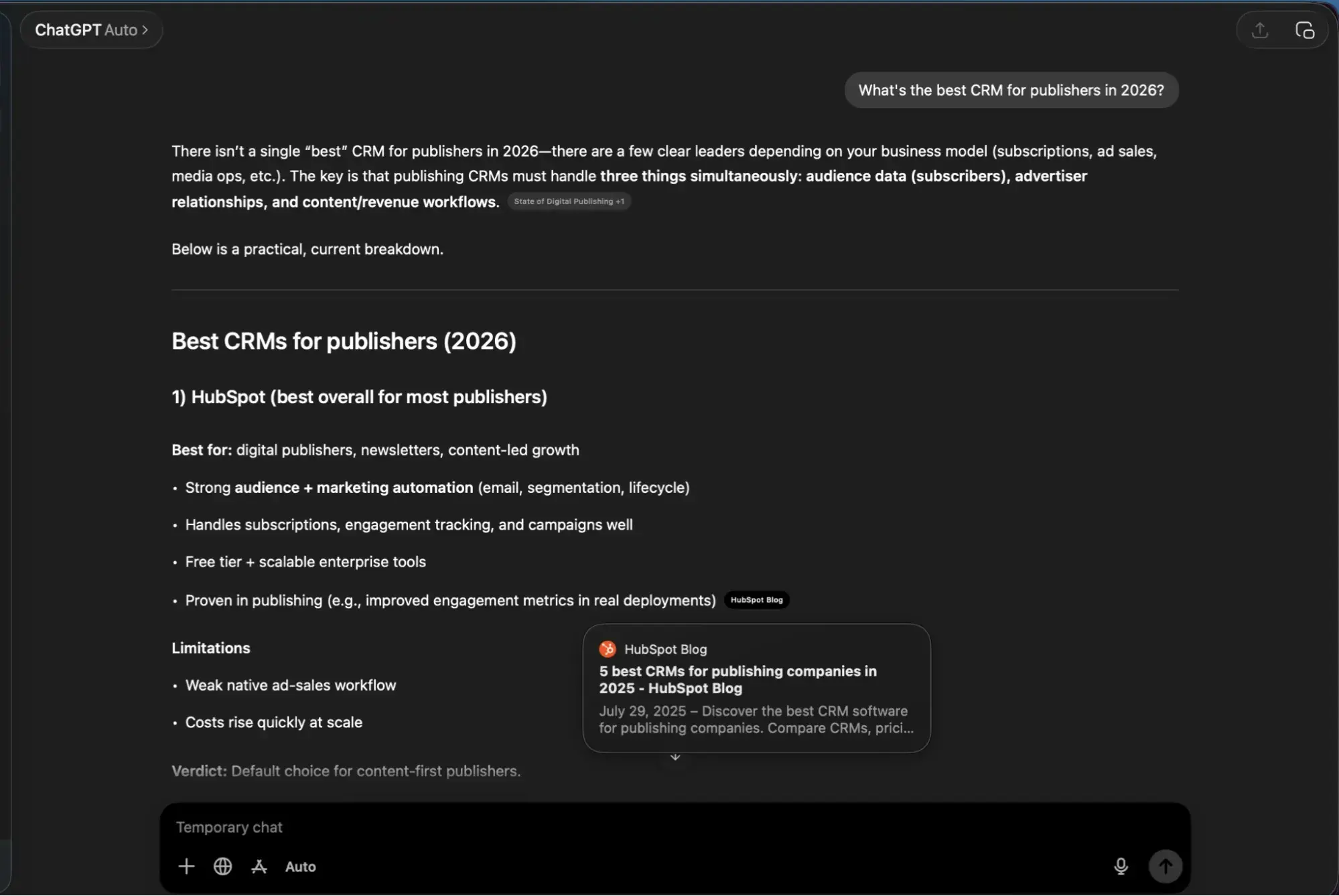
A critical feature of ChatGPT’s "Thinking Mode" is a process known as "query fan-out." When a user enters a single prompt, the AI may decompose it into multiple sub-queries to gather a comprehensive answer. For example, a prompt asking for the "best CRM for publishers" might be broken down into searches for "CRM features for media companies," "HubSpot for publishers reviews," and "top-rated publishing software 2026." Marketers must therefore optimize not just for the primary keyword, but for the logical sub-queries the AI is likely to generate.
The Role of Structured Data and Off-Site Authority
Beyond the content on the page, AI models look for "consensus" across the web to verify the reliability of a source. This is the AI equivalent of Google’s E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness).
Schema Markup as a Native Language
Schema markup—specifically JSON-LD—acts as a translator for AI. By using Organization, Article, and FAQ schema, a website provides the AI with a structured map of its entities. While schema does not guarantee a citation, it removes the ambiguity that often causes an AI to bypass a site in favor of a more clearly structured competitor.
The Third-Party Consensus Requirement
A McKinsey analysis recently highlighted a startling statistic: only 5-10% of citations in AI-generated search results come from a brand’s own website. The remaining 90-95% are drawn from third-party sources including:
- Review Platforms: G2, Capterra, Yelp, and Trustpilot.
- Community Forums: Reddit and Quora.
- Media Coverage: News outlets and industry-specific trade journals.
- Encyclopedic Sources: Wikipedia and Wikidata.
AI models are programmed to seek agreement between sources. If a brand claims to be "the most eco-friendly pest control in Atlanta" on its own site, but no third-party reviews or news articles corroborate that claim, the AI is unlikely to repeat it.
Measuring AEO Success: New Metrics for a New Era
Traditional metrics like "keyword rank" are becoming less relevant in a world of personalized, generative answers. Instead, organizations are adopting AEO-specific KPIs:
- Brand Visibility Score: The percentage of times a brand is mentioned or cited across a set of priority prompts.
- Share of Voice (SoV): A comparison of a brand’s citation frequency versus its top three competitors for specific industry queries.
- Citation Path Analysis: Tracking whether the AI is pulling from a brand’s blog, a social media thread, or a third-party review site to identify where the brand’s "authority" actually resides.
Common Pitfalls and Strategic Misconceptions
As AEO matures, several common mistakes have emerged that can inadvertently sabotage a brand’s AI visibility.
- Image-Only Data: AI crawlers are currently text-centric. Placing critical information—such as pricing tables or product specifications—inside images or infographics makes that data invisible to ChatGPT. All essential data must be available in parsable text or HTML tables.
- The "llms.txt" Distraction: A proposed standard called "llms.txt" was introduced as a way to provide a sitemap for AI. However, major platforms including Google and OpenAI have not yet confirmed its use in their ranking or retrieval algorithms. Current data suggests that for small to mid-sized teams, resources are better spent on Schema and content restructuring than on maintaining experimental text files.
- Stale Content: ChatGPT demonstrates a strong preference for "freshness," particularly for queries related to technology, pricing, and statistics. Data suggests that ChatGPT’s search frequency is significantly higher than Google’s, meaning content updates can be reflected in AI answers within hours rather than days.
Implications for the Future of Information
The rise of AEO represents a fundamental shift in how the internet is consumed. We are moving toward a "zero-click" environment where the goal of a marketer is not necessarily to drive traffic to a website, but to ensure that the brand is the "knowledge base" upon which the AI builds its response. This requires a holistic approach that combines technical rigor, editorial clarity, and aggressive reputation management across the digital ecosystem. As AI models continue to evolve in their reasoning capabilities, the brands that prioritize being "useful" to the model will be the ones that remain visible to the consumer.



{kind=link}