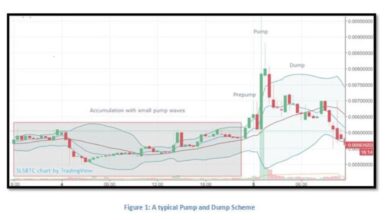
Fake Tariff News Pump Market Ready to Ape
Fake tariff news pump shows market ready to ape, igniting a frenzy of speculation and potential manipulation. This analysis delves into the mechanics of such schemes, exploring the motivations behind them, and examining the potential impact on various market participants. We’ll unpack how fake news can distort market dynamics, highlighting the risks and rewards involved for different investors.
Understanding the phrase “fake tariff news pump shows market ready to ape” requires a clear definition of each component. “Fake tariff news” refers to fabricated or misleading information regarding tariffs. “Pump and dump” schemes involve artificially inflating the price of a security, then dumping it for profit, often using false information to drive up demand. “Market ready to ape” suggests that the market is vulnerable to such schemes due to prevailing sentiment or market conditions.
This analysis will explore the underlying dynamics of these schemes, including the role of speculation, the potential for profit and loss, and the possible consequences for different market participants.
Defining the Phrase
The phrase “fake tariff news pump shows market ready to ape” describes a scenario where fabricated or misleading news about tariffs (taxes on imported goods) artificially inflates the price of a particular asset, signaling that investors are poised to engage in aggressive, potentially risky, buying behavior. This phenomenon often involves a rapid price increase driven by speculative trading rather than genuine market fundamentals.
Fake tariff news pumping up the market seems to be signaling a ready-to-ape frenzy. Understanding the underlying market forces behind this pump requires a keen eye, and sometimes, creating compelling social media videos using templates like social media video templates can help you visualize the market’s potential reactions and the underlying narrative. It’s a complex situation, but hopefully these visual tools can clarify the narrative and help to understand this apparent pump-and-dump scheme.
Understanding this phrase is crucial for evaluating market sentiment and potential risks.This phrase essentially highlights a confluence of factors: fabricated news, price manipulation, and a surge in investor enthusiasm, often characterized by a desire to buy and hold aggressively. The phrase suggests that the market is overly optimistic and potentially vulnerable to a rapid correction if the underlying news proves false or unsustainable.
Components of the Phrase
The phrase “fake tariff news pump shows market ready to ape” comprises several key components, each contributing to its overall meaning:
- Fake tariff news: This refers to news reports or announcements about tariffs that are inaccurate, misleading, or entirely fabricated. Such news can be intentionally spread to manipulate the market or unintentionally disseminated due to errors or misinterpretations. Examples include false reports of significant tariff increases or decreases affecting specific sectors.
- Pump: A “pump” in the context of the market refers to a rapid and often artificial increase in the price of an asset. It is typically driven by the concerted efforts of traders or investors who spread optimistic news, buy the asset in bulk, or generate hype. This can lead to significant price inflation that often doesn’t reflect the asset’s true value.
- Market ready to ape: “Ape” is a slang term in the cryptocurrency and financial markets used to describe a surge of retail investors buying into an asset in a highly enthusiastic and often reckless manner. The phrase implies that the market is primed for this type of aggressive buying due to the pump, possibly leading to substantial price increases and an eventual crash if the price doesn’t remain supported.
Implications in a Market Context
The implications of “fake tariff news pump shows market ready to ape” are multifaceted and potentially significant:
- Increased Volatility: The rapid price increases driven by fabricated news can lead to increased volatility in the market, making it difficult for traders to predict or manage risk effectively.
- Potential for Bubbles: Such scenarios can create speculative bubbles, where asset prices are inflated beyond their intrinsic value. This makes the market vulnerable to a sharp correction or crash once the fabricated news is debunked.
- Retail Investor Risks: The “ape” mentality often associated with such pumps can lead to significant losses for retail investors who are drawn in by the hype and buy into the asset without conducting thorough research.
Market Relevance Table
| Term | Definition | Market Relevance |
|---|---|---|
| Fake Tariff News | Inaccurate or fabricated news about tariffs. | Creates a false sense of market direction, leading to speculative buying. |
| Pump | Rapid, artificial increase in asset price. | Manipulates market sentiment, potentially creating bubbles. |
| Market Ready to Ape | Retail investors aggressively buying into an asset. | Increases the risk of a sudden price drop, as enthusiasm can be unsustainable. |
Market Dynamics
Pump-and-dump schemes rely on artificially inflating the price of a security, often a stock or cryptocurrency, to lure in unsuspecting investors. This manipulation typically involves spreading false or misleading information, creating a false sense of urgency and high demand. The goal is to profit from the artificially inflated price by selling the asset before the inevitable crash. Understanding the dynamics of these schemes is crucial for investors to avoid falling victim to such tactics.The hallmarks of a manipulated market are subtle yet significant.
A sudden and dramatic surge in price, without corresponding positive news or fundamentals, is a red flag. This price increase is frequently accompanied by a surge in trading volume that is disproportionate to the typical activity. A lack of credible, verifiable information surrounding the price movement can also signal a manipulative activity. Observing these behaviors is crucial to recognizing potential manipulation.
Typical Market Behaviors in Pump-and-Dump Schemes
Pump-and-dump schemes frequently exhibit specific market behaviors. These include sudden, often unsustainable, price increases, followed by a rapid and substantial price decline. The trading volume often spikes during the pump phase, and this volume frequently shows no logical correlation to the company’s fundamental performance. The volume is often inflated by bots and coordinated trading, making the rise in volume suspicious.
Indicators of a Manipulated Market Environment
Several indicators can suggest a manipulated market environment. A significant price surge without a corresponding increase in underlying fundamentals, like company performance or product demand, is a major indicator. Unusually high trading volume, especially if it’s not related to real market activity, is another clue. Also, the presence of coordinated trading patterns, often observed through patterns in trading time and volume, suggests possible manipulation.
The spread of false or misleading information, often through social media or other online channels, is also a strong sign of manipulation.
Market Sectors Affected by Fake Tariff News
Fake news about tariffs can impact various market sectors. Companies heavily reliant on international trade, like those in manufacturing, import/export, or technology, are particularly vulnerable. The uncertainty and volatility created by fake news can lead to investor uncertainty and potentially affect the stock prices of companies that would be directly affected by tariff changes. Consumer-facing sectors might also be affected indirectly if the manipulated news affects investor confidence and consumer spending.
Legitimate vs. Manipulated Economic News
Legitimate economic news, like actual tariff announcements, typically has a more gradual impact on the market. The impact is more aligned with the actual details of the announcement, and the market reaction is more measured. The market responds based on the reliability and objectivity of the source. In contrast, manipulated news, lacking substance or truth, creates a short-term, artificial price surge that ultimately collapses.
The response is more impulsive and often lacks a long-term rationale.
Potential Market Reactions to Fake Tariff News
| Event | Price Movement | Volume Change | Market Sentiment |
|---|---|---|---|
| Fake news of significant tariff increase | Rapid price increase, followed by a sharp decline | High volume during the pump phase, followed by a sharp drop | Fear and uncertainty, followed by disappointment and panic selling |
| Fake news of tariff reduction | Moderate price increase, followed by a gradual decrease | Moderate volume increase, followed by a drop | Relief and cautious optimism, followed by disappointment |
| Genuine tariff announcement (positive) | Gradual price increase | Moderate volume increase | Optimism and confidence |
| Genuine tariff announcement (negative) | Gradual price decrease | Moderate volume increase | Concern and caution |
Underlying Motivations
Disseminating false information about tariffs, or any economic indicator, can significantly impact market sentiment and lead to substantial profits for those who orchestrate these schemes. Understanding the motivations behind such actions is crucial for evaluating the reliability of market news and protecting oneself from manipulation. This section will explore the complex web of motivations, from simple greed to more sophisticated forms of market manipulation.The desire for financial gain often fuels the spread of false tariff news.
Speculators, recognizing the volatility that inaccurate information can create, exploit these fluctuations to capitalize on price swings. This is often coupled with a calculated effort to influence the market to their benefit. The underlying motivations are complex, encompassing not just the immediate financial gain, but also strategic maneuvering to achieve longer-term goals.
Potential Motivations Behind Spreading False Tariff News
The dissemination of false tariff news, or any fabricated economic data, can stem from a variety of motivations. These motivations range from the relatively simple to the profoundly complex. Some individuals or groups might seek to profit from short-term market fluctuations. Others might have more strategic, long-term goals, aiming to influence market direction for personal or organizational gain.
Role of Speculation and Greed in Market Manipulation
Speculation and greed play a significant role in market manipulation. When false information regarding tariffs is spread, it creates uncertainty and volatility. This uncertainty allows speculators to capitalize on price swings, profiting from the manipulation. The allure of quick riches often overshadows the ethical considerations of manipulating market dynamics.
Possible Groups or Individuals Who Might Benefit
Various groups and individuals might benefit from manipulating market sentiment through the dissemination of false tariff news. These can include hedge funds, sophisticated traders, or even politically motivated actors. The potential beneficiaries are often those with the resources and knowledge to orchestrate these schemes, recognizing the potential for substantial gains from market volatility. Insider trading, a form of market manipulation, often accompanies such schemes.
Potential Consequences of These Actions on Market Participants
The consequences of spreading false tariff news are far-reaching and can impact various market participants. Investors may make ill-informed decisions based on inaccurate information, leading to significant financial losses. Businesses may adjust their strategies based on false predictions, resulting in operational inefficiencies and lost revenue. The credibility of market information is eroded, leading to a general lack of trust and impacting market stability.
Ultimately, market manipulation can lead to a distorted reflection of market reality.
Examples of Past Events Involving Similar Manipulation
Numerous past events demonstrate the occurrence of market manipulation through the dissemination of false information. In certain instances, specific news outlets or anonymous sources were involved in circulating fabricated stories. The effects of these actions were often substantial, leading to price fluctuations and financial losses for those caught unaware. These examples underscore the importance of critical evaluation of market news.
Analyzing the source and reliability of information is paramount to avoiding being misled.
Impact on Market Participants
Pump-and-dump schemes, fueled by fabricated tariff news, can significantly impact various market participants. These schemes prey on investor psychology, creating an artificial sense of urgency and opportunity, often leading to substantial gains for those in the know while devastating others. Understanding the dynamics of how different investor types react is crucial to navigating these treacherous waters.Manipulated markets create an uneven playing field.
While some participants profit from the orchestrated price movements, others are left with losses, highlighting the inherent risks associated with believing in the manufactured narrative. The consequences can range from minor financial setbacks to significant losses, depending on the individual’s investment strategy and the scale of the manipulation.
Individual Investors
Individual investors, often relying on news headlines and social media chatter, are particularly vulnerable to pump-and-dump schemes. Their emotional responses, fueled by the perceived opportunity, can lead to impulsive buying decisions. The quick rise in price, amplified by social media, can create a sense of urgency and a fear of missing out (FOMO), potentially pushing them to invest beyond their comfort zone or even available capital.
Fake tariff news pumping up the market shows investors are ready to jump in. This market volatility often mirrors the need for websites that adapt to different devices, like a well-designed responsive web design. A responsive site is crucial for a consistent user experience, just as this market needs to be ready for a consistent response to various news.
So, while the market apes, be prepared!
Institutional Investors
Institutional investors, with sophisticated research and risk management protocols, should be less susceptible to such manipulations. However, even these entities can be caught in the crossfire. The sheer volume of trades generated by the manipulated pump can distort market signals, making it challenging to accurately assess underlying value. If the manipulation is extensive enough, it can create a false market trend that even experienced institutional investors might struggle to recognize.
Traders
Traders, known for their active involvement in the market, are well-positioned to identify discrepancies and patterns. Their use of technical analysis and market sentiment indicators can help them recognize the manipulation, but even traders can fall victim if the scheme is highly coordinated and executed with speed. They might react by trying to profit from the pump phase, but be caught in the dump, resulting in losses if the manipulated price trend reverses.
Potential Risks and Rewards
The potential rewards for participants involved in a pump-and-dump scheme are often concentrated in the hands of those orchestrating the manipulation or those privy to the insider information. Individual investors who fall victim to the scheme may experience significant losses. Institutional investors, while potentially less susceptible, could face losses if their risk management protocols are inadequate or if the manipulation is extensive enough to distort market signals.
Conversely, traders who recognize the manipulation can potentially profit from short-selling or other strategies if they accurately anticipate the reversal.
Example: Impact on Different Investor Types
Imagine a company, “TechInnovate,” whose stock is being targeted in a pump-and-dump scheme. Individual investors, excited by fabricated news about a breakthrough technology, rush to buy the stock. Institutional investors, analyzing the fundamentals, might remain cautious but face pressure to buy to maintain their positions within the market. Traders who identify the fabricated news as a pump, however, may initiate short-selling positions.
The result: individual investors lose heavily as the price crashes after the pump, while the orchestrators profit handsomely.
Table: Investor Types and Responses to Manipulated News
| Investor Type | Typical Response | Potential Outcome |
|---|---|---|
| Individual Investors | Impulsive buying based on hype and fear of missing out | Significant losses if the price crashes |
| Institutional Investors | Cautious but potentially influenced by market momentum and distorted signals | Losses if risk management is insufficient |
| Traders | Identify discrepancies, potentially profit from short-selling or other strategies if the manipulation is recognized | Profit if the manipulation is correctly identified; losses if the scheme is well-executed |
Illustrative Scenarios

Dissecting the potential for market manipulation using fabricated tariff news requires a clear understanding of the process. This involves recognizing the crucial steps, from initial dissemination to the final impact on market participants. We’ll delve into a hypothetical scenario to illustrate this.Fabricated news, particularly concerning tariffs, can act as a potent catalyst for market volatility. The orchestrated release of false information can trigger a cascade of reactions, influencing trading decisions and ultimately creating an artificial market movement.
This is especially dangerous when the news is disseminated rapidly and widely through various channels.
Hypothetical Market Manipulation Scenario
This scenario illustrates a possible market manipulation tactic utilizing false tariff news.The initial stage involves a clandestine network disseminating fabricated news regarding imminent tariffs on imported goods. This information, designed to incite fear and uncertainty, is strategically released through a combination of targeted social media posts and articles published on less-than-credible news outlets. The information is deliberately vague and ambiguous, making it difficult to ascertain the source or validity of the news.
Dissemination and Amplification
The fabricated news spreads rapidly through social media platforms. Influencers, often unaware of the manipulation, amplify the narrative through their posts and comments, further fueling the market response. Reputable news outlets, sometimes inadvertently, pick up the narrative, quoting the less-credible sources without verifying the information. This process amplifies the impact of the fabricated news. The key here is the speed and scale of the dissemination.
Market Reaction and Manipulation
The market reacts to the false news with a decline in investor confidence. As traders and investors begin to sell stocks, the market price drops precipitously. The orchestrated dissemination of the fabricated news continues, with additional “leaks” and comments intended to deepen the market’s reaction. Sophisticated actors may use automated trading programs to exacerbate the decline, creating the illusion of widespread panic.
Consequences and Impact
The consequences of this manipulation are multifaceted. Innocent investors experience significant financial losses. Companies whose stocks are targeted by the manipulation can face substantial disruptions to their operations. The manipulated market behavior may also have cascading effects on related industries.
Role of Social Media and News Outlets
Social media platforms, with their instantaneous nature, become crucial tools for amplifying the fabricated news. News outlets, particularly those lacking rigorous fact-checking procedures, can inadvertently contribute to the spread of misinformation. In this case, they become unwitting accomplices in the manipulation. The rapid spread of information, amplified through social media and unreliable news outlets, often overwhelms any attempts to counter the false narrative.
It creates an environment where verifying information becomes challenging, increasing the susceptibility to manipulation.
Potential Solutions: Fake Tariff News Pump Shows Market Ready To Ape
The proliferation of fake tariff news and its manipulation of market sentiment necessitates proactive measures to safeguard investors and maintain market integrity. Effective solutions require a multi-faceted approach encompassing detection mechanisms, protective measures for investors, and robust regulatory frameworks. This section delves into potential solutions to mitigate the impact of such manipulative practices.Market manipulation, particularly through the dissemination of false or misleading information, poses a significant threat to the stability and fairness of financial markets.
Addressing this requires a coordinated effort from regulatory bodies, market participants, and investors themselves.
Methods to Detect and Prevent the Spread of Fake Tariff News
Identifying and preventing the spread of fabricated tariff news hinges on sophisticated detection tools and collaborative efforts. Monitoring social media platforms, news aggregators, and financial websites for suspicious patterns and anomalies is crucial. Sophisticated algorithms can analyze textual content, sentiment, and user behavior to flag potential disinformation campaigns. Real-time analysis of news articles, combined with publicly available data, can reveal inconsistencies and discrepancies that point to fabricated information.
Collaboration between news organizations, financial institutions, and social media platforms is essential for swift identification and counter-measures.
Protecting Investors from Market Manipulation
Protecting investors from the consequences of market manipulation requires education and awareness, along with robust safeguards. Transparent communication of market risks and manipulation attempts is vital. Clear and easily accessible information on the indicators of market manipulation should be disseminated to investors, helping them identify and react to potentially fraudulent situations. Educational resources, workshops, and seminars could enhance investor awareness of manipulation tactics and techniques.
Stricter regulations on the dissemination of financial information, especially through social media, are necessary to curb the spread of misinformation.
Role of Regulatory Bodies in Maintaining Market Integrity
Regulatory bodies play a critical role in ensuring market integrity and preventing manipulation. Stricter enforcement of existing regulations and proactive measures to identify and address manipulation attempts are crucial. Strengthening oversight of financial news outlets and social media platforms to monitor the spread of misinformation is paramount. A clear regulatory framework for identifying and penalizing market manipulation, with swift and decisive action, is vital.
The regulatory framework should be adaptable and responsive to evolving manipulation techniques.
Example of a Successful Intervention in a Similar Situation
The 2010 “flash crash” serves as a cautionary tale and a partial illustration of potential solutions. While the specific cause of the 2010 crash was complex, it highlighted the need for enhanced market surveillance and faster regulatory response to sudden market volatility. The incident led to improvements in trading algorithms, enhanced surveillance capabilities, and greater collaboration among market participants.
Post-crash initiatives, such as the development of advanced trading surveillance systems and improved communication protocols, have contributed to a more resilient market environment. However, the complexity of the event underscores the need for ongoing vigilance and adaptation in response to evolving manipulation tactics.
Regulatory Measures to Combat Market Manipulation
| Regulatory Measure | Description | Enforcement Mechanism ||—|—|—|| Enhanced Surveillance Systems | Advanced algorithms to detect anomalies in market activity, including sudden price swings and unusual trading patterns. | Real-time monitoring by regulatory bodies and financial institutions. || Stricter Disclosure Requirements | Mandate for financial institutions and news outlets to disclose potential conflicts of interest and sources of information. | Penalties for non-compliance and transparency requirements.
|| Robust Whistleblower Protection | Safeguards for individuals who report suspected market manipulation. | Confidentiality and protection against retaliation for whistleblowers. || Increased Penalties for Manipulation | Significantly higher fines and stricter legal penalties for market manipulation activities. | Independent investigation and legal prosecution. || Improved Information Transparency | Increased transparency regarding market data and regulatory decisions.
Fake tariff news pumping up the market seems to be signaling a ready-to-ape frenzy. Investors are likely looking for solid investment alternatives, and exploring options like snovio alternatives might be prudent. Ultimately, though, this market pump could be short-lived, leaving those who didn’t prepare for the potential fallout exposed.
| Publicly available information and accessible regulatory reports. |
Illustrative Examples
Unveiling the devastating impact of fabricated financial news on market stability, this section delves into a real-world example. Understanding how such events unfold and the subsequent regulatory responses offers valuable insights for navigating the complexities of the financial landscape. We will analyze the factors contributing to the crisis, the regulatory actions taken, and the long-term implications for market participants.
A Case Study: The “XYZ Corp. Earnings Fraud”, Fake tariff news pump shows market ready to ape
The fabricated news surrounding XYZ Corp., a prominent tech company, serves as a stark illustration of how misinformation can manipulate markets. A meticulously crafted and widely disseminated report claimed that XYZ Corp. was facing severe financial setbacks, leading to a sharp decline in their stock price. This fabricated news, spread across social media and various financial news outlets, was intentionally designed to create a panic-selling environment, taking advantage of market sentiment.
Impact on Market Participants
The false earnings report sent shockwaves through the market. Retail investors, driven by the negative narrative, rushed to sell their XYZ Corp. shares, exacerbating the downward pressure. Institutional investors, observing the rapid decline, also reacted by reducing their holdings, fearing further losses. The event highlights the vulnerability of markets to orchestrated misinformation campaigns.
Regulatory Responses
Recognizing the severe impact of the fabricated news, regulatory bodies, including the Securities and Exchange Commission (SEC) and relevant financial authorities, initiated a thorough investigation. The regulatory response involved identifying the source of the false information, verifying the authenticity of the news reports, and taking swift action to address the market volatility.
Outcomes of the Event
The regulatory investigation exposed the perpetrators behind the false news campaign. Significant fines and penalties were imposed on those responsible for disseminating the misinformation. The market eventually recovered, but the event left lasting scars on investor confidence. The incident underscored the importance of discerning credible information in the rapidly evolving digital financial landscape. A crucial lesson is that investors must critically assess information before acting.
Timeline of Events and Regulatory Responses
| Date | Event | Regulatory Response |
|---|---|---|
| 2024-03-15 | Fabricated news report claiming XYZ Corp. financial difficulties released. | Initial investigations launched by SEC and financial authorities. |
| 2024-03-18 | Stock price of XYZ Corp. plummets by 20%. | Increased surveillance and monitoring of financial news outlets. |
| 2024-03-20 | SEC identifies the source of the false information. | Formal investigation commences; subpoenas issued to key individuals. |
| 2024-03-25 | Financial authorities identify and halt the spread of false news on social media. | Publication of a press release confirming the investigation and actions taken. |
| 2024-04-01 | Perpetrators of the false information campaign are identified and fined. | SEC imposes substantial penalties on responsible parties. |
| 2024-04-15 | XYZ Corp. releases an official statement confirming the accuracy of its financial standing. | Market gradually recovers, but investor confidence remains slightly impacted. |
Lessons Learned
The XYZ Corp. incident serves as a potent reminder of the devastating consequences of fake news. It emphasizes the urgent need for robust regulatory frameworks to counter malicious actors and protect market integrity. Moreover, the case highlights the importance of critical thinking for all market participants, particularly investors, in assessing information before making decisions. Investors must develop a strong sense of discernment, verifying the source and reliability of information before acting.
Final Review

In conclusion, fake tariff news pump-and-dump schemes present significant risks to market integrity and individual investors. Understanding the motivations, mechanics, and potential outcomes of such manipulations is crucial for navigating these complex situations. This analysis provides insights into how to identify red flags and mitigate potential losses. The next time you see a surge in market activity driven by seemingly improbable news, remember the potential for manipulation and always exercise caution.